【LLM】ChatGPT 训练范式

Stage 1: PT(Continue PreTraining),增量预训练
- 使用百科类文档类数据集,用来在领域数据集上增量预训练或二次预训练,期望能 把领域知识注入给模型 ,以医疗领域为例,希望增量预训练,能让模型理解感冒的症状、病因、治疗药品、治疗方法、药品疗效等知识,便于后续的SFT监督微调能激活这些内在知识。
- 这里说明一点,像GPT3、LLaMA这样的大模型理论上是可以从增量预训练中获益,但增量预训练需要满足两个要求:1)高质量的预训练样本;2)较大的计算资源,显存要求高,即使是用LoRA技术,也要满足block_size=1024或2048长度的文本加载到显存中。
- 其次,如果你的项目用到的数据是模型预训练中已经使用了的,如维基百科、ArXiv等LLaMA模型预训练用了的,则这些数据是没有必要再喂给LLaMA增量预训练,而且预训练样本的质量如果不够高,也可能会损害原模型的生成能力。
- tips:PT阶段是可选项,请慎重处理。
- 训练数据集示例(相关领域的大段文本即可):
1
传染病是指由病原微生物,如朊粒、病毒、衣原体、立克次体、支原体(mycoplasma)细菌真菌、螺旋体和寄生虫,如原虫、蠕虫、医学昆虫感染人体后产生的有传染性、在一定条件下可造成流行的疾病。感染性疾病是指由病原体感染所致的疾病,包括传染病和非传染性感染性疾病。
【模型变化】:基于llama-7b模型,使用医疗百科类数据继续预训练,期望注入医疗知识到预训练模型,得到llama-7b-pt模型
Stage 2: SFT(Supervised Fine-tuning),有监督微调
- 人工准备大量的 输入-输出 对话示例(比如用户提问 + 高质量的回答),用这些数据继续训练模型
- 训练数据集示例:
- 指令-回复格式(例如InstructGPT)
1
2{"instruction": "请用中文解释量子纠缠是什么", "input": "", "output": "量子纠缠是指两个或多个粒子之间存在一种特殊的关联状态,即使它们相隔很远,对一个粒子的测量会即时影响另一个粒子的状态。"}
{"instruction": "写一首五言绝句关于秋天", "input": "", "output": "秋风起兮叶落黄,寒意渐深夜渐长。"}
- 指令-回复格式(例如InstructGPT)
- 对话格式(例如ChatGPT)
1
2{"conversations":[{"from":"human","value":"你好,介绍一下爱因斯坦的相对论。"},{"from":"assistant","value":"相对论包括狭义和广义相对论,主要描述空间、时间和引力的关系。"}]}
{"conversations":[{"from":"human","value":"帮我写一首诗,主题是春天。"},{"from":"assistant","value":"春光明媚花正开,柳绿桃红映天台。小鸟欢歌声声脆,万物复苏景色佳。"}]}
- 对话格式(例如ChatGPT)
【模型变化】:基于llama-7b-pt模型,使用医疗问答类数据进行有监督微调,得到llama-7b-sft模型
Stage 3: RLHF(Reinforcement Learning from Human Feedback)
RM(Reward Model),奖励模型建模
原则上,我们可以直接用人类标注来对模型做 RLHF 微调。
然而,这将需要我们给人类发送一些样本,在每轮优化后计分。这是贵且慢的,因为收敛需要的训练样本量大,而人类阅读和标注的速度有限。
一个比直接反馈更好的策略是,在进入 RL 循环之前,用人类标注集来训练一个 奖励模型(RM) 。RM的目的是模拟人类对文本的打分。
构建奖励模型的最佳实践是预测结果的排序,即对每个 prompt (输入文本) 对应的多个结果,模型预测人类标注的比分哪个更高。
RM模型是通过人工标注SFT模型的打分结果来训练的,目的是取代人工打分,本质是个回归模型,用来对齐人类偏好,主要是”HHH”原则,具体是”helpful, honest, harmless”。
训练数据集示例:
1
2
3
4
5
6
7{
"system": "",
"history": [],
"question": "用一句话形容春天",
"response_chosen": "春天充满了生机和希望。",
"response_rejected": "春天是一个季节。"
}或:
1
2
3
4
5
6
7{
"instruction": "用一句话形容春天",
"input": "",
"response_1": "春天充满了生机和希望。",
"response_2": "春天是一个季节。",
"better": 1
}
【模型变化】:基于llama-7b-sft模型,使用医疗问答偏好数据训练奖励偏好模型,训练得到llama-7b-reward模型
RL(Reinforcement Learning),强化学习
- RL(Reinforcement Learning)模型的目的是最大化 RM 的输出,基于上面步骤,我们有了微调的语言模型(llama-7b-sft)和奖励模型(llama-7b-reward),可以开始执行 RL 循环了。
- 这个过程大致分为三步:
- 输入prompt,模型生成答复
- 用奖励模型来对答复评分
- 基于评分,进行一轮策略优化的强化学习(Proximal Policy Optimization,PPO)
- PPO的目标是让语言模型生成能够从奖励模型那里获得高分的回答
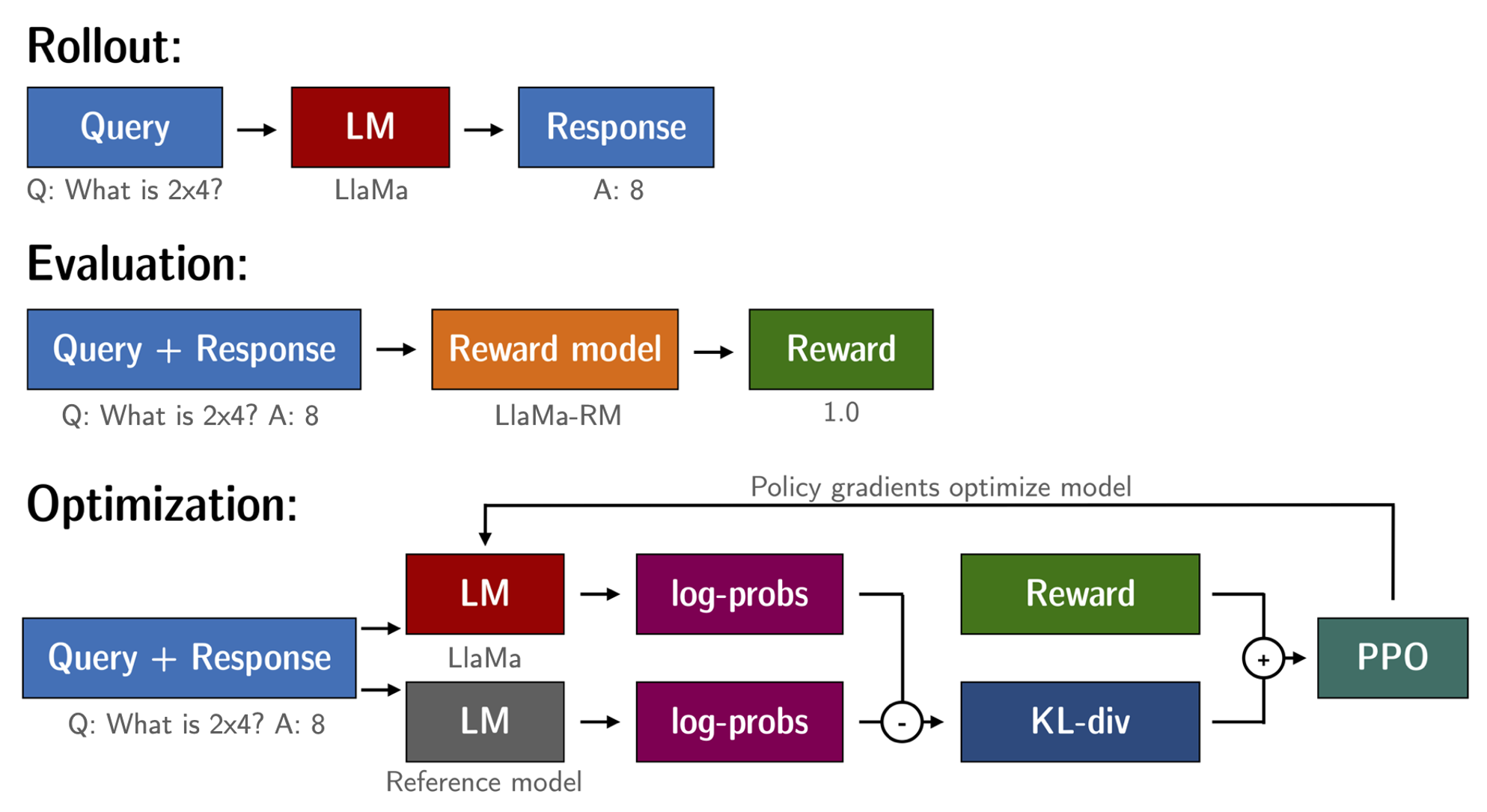
【模型变化】:基于llama-7b-reward模型 RL 微调训练llama-7b-sft模型,得到llama-7b-rl模型
PPO 的改进版本
DPO (Direct Preference Optimization),直接偏好优化
- DPO方法绕开了训练奖励模型和复杂的强化学习循环,可以通过直接优化语言模型来实现对其行为的精确控制,而无需使用复杂的强化学习。
- DPO 将奖励函数和最优策略之间的映射联系起来,从而把约束奖励最大化问题转化为一个单阶段的策略训练问题。 这种算法不仅不用拟合奖励模型,还避免了在微调过程中从语言模型中采样或调整超参数的需要。
- 具体来说,DPO 的损失函数会直接鼓励模型提高“选择的回答”的概率,同时降低“拒绝的回答”的概率。
- 实验结果表明,DPO 算法可以与现有RLHF方法一样有效地从人类偏好中学习,甚至在某些任务中表现更好,比如情感调节、摘要和单轮对话。
ORPO (Odds Ratio Preference Optimization),比值比偏好优化
- ORPO 是 DPO 的一种改进,它将指令微调(SFT)和偏好对齐(Preference Tuning)合并为单个阶段,缓解模型灾难性遗忘问题。
GRPO (Generalized “Rejection Sampling” Preference Optimization)
- GRPO可以看作是对 DPO 思想的扩展和泛化,它将“拒绝采样”这一经典方法的思想融入到偏好优化中,提供了一种更广义的优化框架。
拓展阅读
- OpenAI 的 InstructGPT 首次提出了以上范式,让GPT3模型能够更好地遵循人类指令。技术报告::https://openai.com/zh-Hans-CN/index/instruction-following/
- ChatGPT 进一步扩展了 InstructGPT,除了指令,还大量加入对话式数据(模拟聊天、问答、角色扮演),并且支持多轮上下文记忆,具有更自然的对话风格。是面向大众的一个产品。技术报告:https://openai.com/zh-Hans-CN/index/chatgpt/
参考
评论