【Agent】基于Lang生态的智能体开发最佳实战
引言
LangChain 和 LangGraph 是目前最流行的 AI Agent 开发框架。LangChain 提供了丰富的工具抽象和 LLM 接口,而 LangGraph 则提供了强大的状态图和工作流控制能力。
本文将基于真实的急诊科分诊智能体项目,介绍如何结合 LangChain 和 LangGraph 构建生产级智能体。
Lang 生态核心概念
LangChain vs LangGraph
在 Lang 生态中,LangChain 和 LangGraph 各有侧重:
LangChain:
- 提供工具抽象(BaseTool)和 LLM 接口
- 适合简单的链式调用和 ReAct Agent
- 基于 Prompt 模板控制流程
- 快速原型开发
LangGraph:
- 提供状态图(StateGraph)和工作流控制
- 适合复杂的多步骤、多分支流程
- 显式的流程控制和状态管理
- 更好的可调试性和可观测性
最佳实践:结合使用
- 使用 LangChain 定义工具(BaseTool)和 LLM 接口
- 使用 LangGraph 构建状态图和工作流
Agent 的核心要素
一个完整的生产级 Agent 通常包含:
- LLM(大语言模型):作为 Agent 的”大脑”,负责推理和决策
- Tools(工具):Agent 可以调用的外部功能,如 API、数据库等
- State(状态):存储对话历史、中间结果和上下文信息
- Graph(状态图):定义 Agent 的执行流程和分支逻辑
- Memory(记忆):持久化对话历史,支持多轮对话
- Checkpointer(检查点):保存和恢复 Agent 状态
实战项目:急诊科分诊智能体
项目背景
我们将构建一个真实的急诊科分诊智能体,它能够:
- 查询患者的既往就诊历史
- 分析患者的检验检查结果
- 结合当前症状进行分诊决策
- 支持多轮对话和上下文记忆
这个项目展示了 LangChain + LangGraph 的最佳实践。
第一步:定义状态(State)
使用 LangGraph 的 StateGraph 定义 Agent 状态结构:
1 | from langgraph.graph.message import add_messages |
必须字段:
messages字段:当 StateGraph 的不同节点都返回 messages 时,不会覆盖,而是自动追加合并成一条对话历史。thread_id:当前会话的唯一标识符,用于会话隔离和记忆管理
第二步:定义工具(Tool)
使用 Pydantic 的 BaseModel 定义参数格式
使用 LangChain 的 BaseTool 定义业务工具
1 | from pydantic import BaseModel, Field |
关键点:
name: 智能体看到的的工具名称args_schema: 使用 Pydantic 定义了参数结构和类型,LLM 生成参数后,在真正执行工具前,Pydantic会校验参数,不合规的参数会被拦截、报错或被要求重试正确调用description: 要详细,帮助 LLM 理解何时使用_run()方法包含业务逻辑(API 调用 + 规则引擎处理)
注:简单的场景下,也可以使用装饰器 @tool 来定义工具。该装饰器会自动从函数名获取name,自动从 docstring 获取 description
第三步:构建 LangGraph 状态图(Graph)
创建一个简单的只有 agent 和 tools 两个节点的 graph (ReAct Agent)
1 | from langgraph.graph import StateGraph, END |
关键点:
call_model()调用 LLMshould_continue()判断是否调用工具,如果返回内容包含"tool_calls",就进入 tools 节点ToolNode自动处理工具调用add_conditional_edges()实现条件分支- 从 agent 节点出发,调用 should_continue
- 如果
should_continue(state)返回"continue"→ 进入"tools"节点 - 如果
should_continue(state)返回"end"→ 结束流程(END)
MemorySaver提供记忆功能
使用以下代码可实现对 agent 状态图的可视化
1 | app = create_agent_graph() |
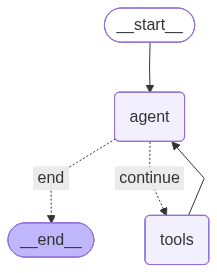
第四步:使用 Agent
1 | app = create_agent_graph() |
记忆管理
1 | # 不同用户使用不同 thread_id 实现会话隔离 |
关键点:
thread_id用于隔离不同用户/会话MemorySaver自动保存和加载历史消息- 内存存储,进程重启后丢失(生产环境可使用 Redis/PostgreSQL)
LangChain ReAct Agent vs LangGraph
LangChain 的 create_react_agent 也可以实现工具调用:
1 | from langchain.agents import create_react_agent, AgentExecutor |
LangChain ReAct Agent 的局限性
- 状态管理不够显式:状态隐藏在 Prompt 中,难以调试
1
2
3
4
5
6
7
8prompt = f"""
Answer the following questions as best you can. You have access to the following tools:
{tools_description}
Question: {question}
Thought: {previous_thoughts} # 状态片段1
Action: {previous_actions} # 状态片段2
""" - 流程控制不够显式:执行路径由 LLM 的文本输出隐式驱动
1
2
3
4
5# 流程控制逻辑隐藏在内部
agent_executor.invoke(...)
# 看不到"什么条件下继续/结束"的决策逻辑
# 看不到"下一步去哪里"的分支定义
# 循环由解析 LLM 输出的 "Action:" 或 "Final Answer:" 决定 - 可观测性差:难以追踪每个步骤的执行情况
- 扩展性受限:添加自定义控制逻辑需要修改 Prompt 模板或继承内部类
LangGraph 的优势
- 显式的流程控制:should_continue 函数显式定义了如何决定下一步
- 灵活的分支逻辑:可以添加任意复杂的条件判断和多路分支用于模型路由等
- 强大的可观测性:可以追踪每个节点的输入输出
- 易于扩展:添加新节点、新边、新决策逻辑只需几行代码
对比表格
| 特性 | LangChain ReAct Agent | LangGraph |
|---|---|---|
| 流程控制 | 基于 Prompt 模板 | 显式状态图 |
| 状态管理 | 隐式(在 Prompt 中) | 显式(TypedDict) |
| 可调试性 | 较差 | 优秀 |
| 扩展性 | 受限 | 灵活 |
| 适用场景 | 快速原型 | 生产级应用 |
Agent vs Workflow:两种架构模式的对比
在实际项目中,我们实现了两种不同的架构模式:chat agent(工具增强型智能体)和 chat workflow(预定义工作流)。通过对比这两种实现,可以更深入地理解 LangGraph 的设计哲学和应用场景。
架构对比
chat agent:工具增强型智能体(Tool-Augmented Agent)
核心特点:LLM 自主决策,动态调用工具
1 | # 状态定义:极简设计 |
工具定义示例:
1 | class PatientHistoryQueryTool(BaseTool): |
流程图:
chat_workflow:预定义工作流(Predefined Workflow)
核心特点:显式定义流程,LLM 在特定节点执行特定任务
1 | # 状态定义:详细的业务字段 |
节点实现示例:
1 | def intent_router_node(state: TriageState) -> TriageState: |
流程图:
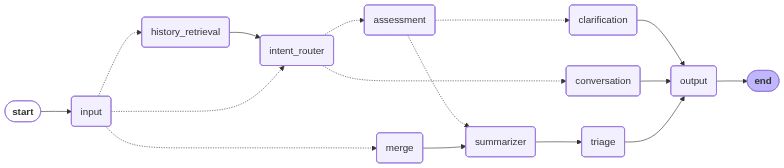
核心差异对比
| 维度 | chat_agent (工具增强型) | chat_workflow (预定义工作流) |
|---|---|---|
| 代码复杂度 | 简洁,只需定义工具 | 冗长,需定义每个节点 |
| 灵活性 | 高,LLM 动态调整 | 低,流程固定 |
| 可预测性 | 低,可能有意外决策 | 高,执行结果稳定 |
| 扩展性 | 易扩展,添加工具即可 | 扩展成本高,需改流程 |
| Token 消耗 | 高,传递完整历史 | 低,只处理必要信息 |
| 适用场景 | 复杂多变的交互任务 | 固定流程的业务场景 |
在实际项目中,可以结合两种模式的优势:
- 主流程使用 Workflow:保证核心业务流程的稳定性
- 特定节点使用 Agent:在需要灵活性的地方引入工具调用
Q&A
Q1: Agent 如何决定是否调用工具?
- 工具的
name和description - System Prompt(系统提示词)中的描述
- 用户的问题/请求(用户提示词)
- 对话上下文(state 中的
messages字段)
Q2: Agent 如何决定工具调用的参数?
- 工具的
description字段 - 每个参数的
description字段(args_schema) - 参数模式
args_schema:既验证 LLM 输出,也影响 LLM 输出的正确性- args_schema 以 JSON Schema 格式,被编码进 LLM 的提示词中,直接影响 LLM 的推理过程
- LLM 生成参数后,Pydantic 会验证输出
- 用户输入中的信息提取
- 对话上下文推理
- System Prompt 中的指导
参考资料
- LangChain 官方文档: https://python.langchain.com/docs/get_started/introduction
- LangGraph 官方文档: https://langchain-ai.github.io/langgraph/
- LangChain GitHub 仓库: https://github.com/langchain-ai/langchain
- LangGraph GitHub 仓库: https://github.com/langchain-ai/langgraph
- LangChain Cookbook: https://github.com/langchain-ai/langchain/tree/master/cookbook